IBM Db2는 저지연 트랜잭션, 실시간 분석, AI 애플리케이션을 대규모로 지원하도록 구축된 클라우드 네이티브 데이터베이스입니다.
데이터 보안, 거버넌스, 확장성, 가용성 분야에서 수십 년간 혁신해온 기술을 바탕으로 데이터베이스 관리자, 엔터프라이즈 아키텍트, 개발자가
다음과 같은 작업을 할 수 있는 단일 엔진을 제공합니다. 모든 클라우드에서 차세대 미션 크리티컬 애플리케이션을 구축하고,
하이브리드 배포로 마이그레이션할 시 지속적인 가용성과 다운타임 제로를 지원합니다.
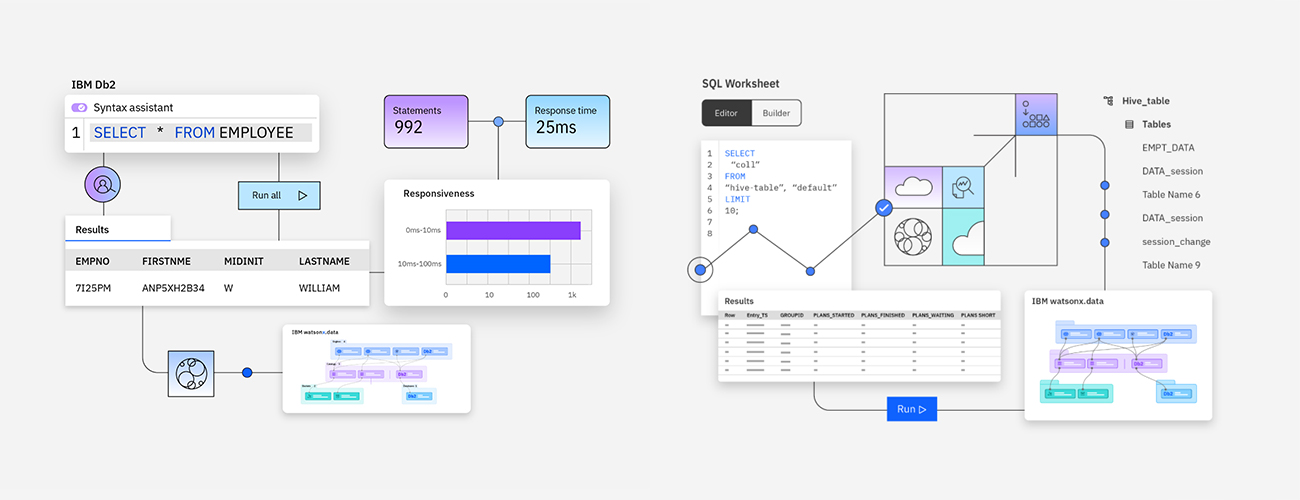

IBM Cloud 및 Amazon RDS에서 완전 관리형 서비스로, 내장 연산자가 포함된 Kubernetes 컨테이너로, 또는 서비스형 인프라로 배포된 Db2를 통해 데이터베이스
관리 및 유지 보수를 간소화하세요.
동적 데이터와 저장 데이터를 보호하고 알려지지 않은 동작을 모니터링 및 감지하며 Db2의 엔드 투 엔드 거버넌스 및 보안 기능을 통해 데이터의 프라이버시를 보장합니다.


단일 멀티 모델 데이터베이스에서 XML, JSON, 텍스트 및 공간 데이터를 지원하여 새로운 데이터, 분석 및 AI 사용 사례까지 해결할 수 있습니다. 또한 Java, .Net, Ruby, Python, R, Perl, C, C++, pureXML, XQuery, Mongo, FLWOR Expression, JSON 등을 지원하여 새로운 애플리케이션을 개발하는 데도 문제 없습니다.
동급 최고의 압축 기능, 확장 가능한 스토리지 및 컴퓨팅, 머신 러닝 기반 쿼리 최적화를 통해 워크로드 요건을 빠짐없이 지원하기 때문에 데이터를 더욱 빠르게 가져올 뿐만 아니라 고성능 애플리케이션도 실행할 수 있습니다.


IBM Cloud의 완전 관리형 SaaS, Amazon RDS, 하이브리드 또는 온프레미스 등 원하는 대로 배포 옵션을 선택할 수 있어 유연성이 높습니다. 또한 Db2 분산형 데이터 기능(DDF)에 완전히 통합된 확장 가능하며 원활한 RESTful API 세트를 통해 Db2 데이터를 웹, 모바일, 클라우드 애플리케이션과 연결합니다.
Db2는 동일한 데이터베이스에서 높은 성능이 필요한 다수의 미션 크리티컬 워크로드(트랜잭션, 분석, 운영)를 실행할 수 있습니다. 또한 데이터를 Db2 Warehouse와 watsonx.data로 피드하여 신뢰할 수 있는 데이터를 사용해 새로운 인사이트와 AI를 구현할 수 있습니다.


IBM 소프트웨어는 SBI가 Db2를 구현하여 재무 운영을 최적화하고 고객 만족도를 높이는 데 중추적인 역할을 했습니다.

Owens-Illinois는 전 세계 자사 데이터베이스 인프라를 IBM Db2로 마이그레이션하여 비용을 절감하고 스토리지 설치 공간을 축소하며
트랜잭션을 더욱 가속화했습니다.

Puma는 IBM Db2 pureScale을 배치하여 데이터베이스 환경이 증가하는 트랜잭션 로드를 처리할 수 있는 성능과 확장성을 갖출 수 있도록 지원했습니다.

Wi2는 20만 개 Wi-Fi 액세스 지점에서 도출한 데이터를 방문자 인사이트를 제공하는 가치 있는 소스로 전환합니다.
IBM Informix는 가장 까다로운 트랜잭션 및 분석 워크로드에 최적화된 고성능, 상시 가동, 확장성이 뛰어나고 쉽게 임베디드할 수 있는 엔터프라이즈급 데이터베이스입니다.
객체 관계형 엔진인 IBM Informix는 최고의 관계형 및 객체 지향 기능을 원활하게 통합하여 복잡한 데이터 구조와 관계를 유연하게 모델링합니다.
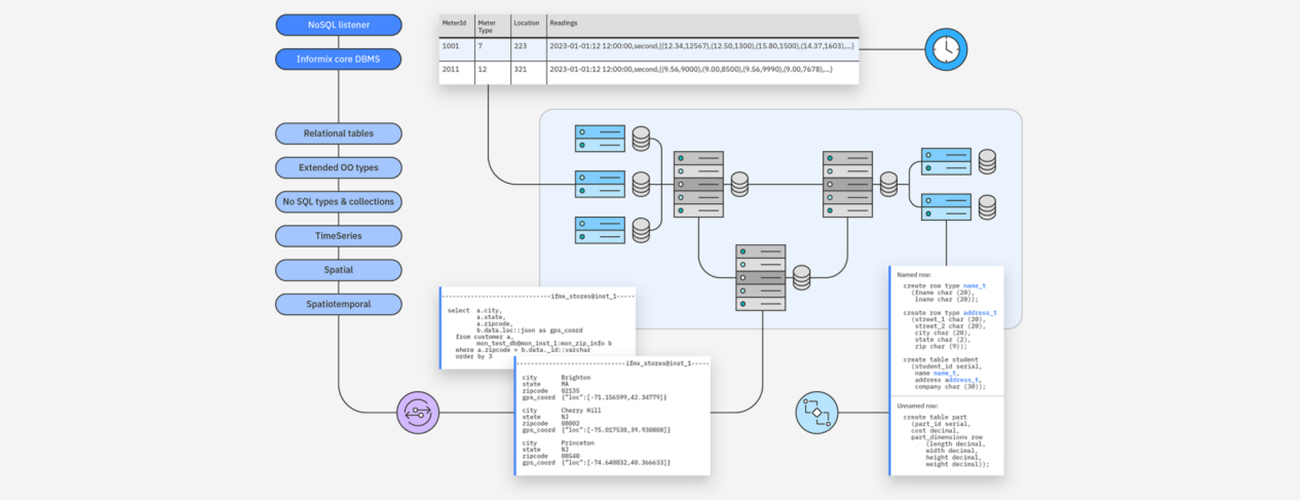

100MB(Raspberry Pi)의 컴팩트한 크기부터 대규모 서버처럼 넓은 공간까지
다양한 설치 공간에서 Informix를 실행하여 엣지 디바이스부터 엔터프라이즈급 서버에 이르는 광범위한 설치 공간에서 실행할 수 있습니다.
최고의 관계형 및 객체 지향 기능을 결합하여 단일 데이터베이스 내에서
복잡한 데이터 구조와 관계를 유연하게 모델링할 수 있습니다.


watsonx.data의 새로운 Informix 커넥터를 사용하여 IBM Informix 및
제로 ETL을 사용하는 기타 데이터 소스의 멀티모달 데이터 유형에 쉽게 액세스하고 쿼리할 수 있습니다.
생산성 가속화 IBM Informix는 임베디드 애플리케이션의
상시 트랜잭션과 실시간 분석에 적합합니다.


하이브리드 클라우드 전반에서 애플리케이션을 위한 고급 가용성,
액티브 클러스터링 및 지역 간 복제를 보장합니다.
클라우드를 통해 어디서나 IBM Informix를 쉽게 배포할 수 있습니다.


Baqueira Beret은 IBM Informix를 통해 지원되는 Deister Software의 Axional 애플리케이션을 사용하여 스키 리조트, 병원 사업 및 여행사라는 세 가지 운영상 독립적인 사업 라인에 대한 통합 제어, 보고 및 감독을 가능하게 합니다. 이를 통해 회사 간 재무 및 기타 데이터를 수동으로 수집하고 편집하는 작업을 없앨 수 있습니다. IBM Informix는 Axional에서 제공하는 분석 기능을 쉽게 충족하는 동시에 자체 관리 및 자동화된 관리 기능을 제공하는 풋프린트 데이터베이스를 제공합니다.


Leolo IT와 Siemens는 Siemens AG의 산업 메타버스 전략의 일환으로 watsonx와 IBM Informix가 지원하는 생성 AI를 활용하여 공동으로 프로토타입을 제작하고 보다 스마트한 업무를 진행합니다.
어디서나 데이터를 통합, 액세스 및 확장할 수 있도록 하여 심층 분석, 비즈니스 인텔리전스, AI 및 머신 러닝(ML) 워크로드를 운영하도록 설계된
클라우드 네이티브 엔터프라이즈 데이터 웨어하우스입니다. Netezza Performance Server 어플라이언스를 차세대 어플라이언스로 현대화하고
SaaS, 하이브리드 또는 온프레미스 등 어디에나 배포하며 새로운 watsonx.data 데이터 스토어와 원활하게 통합할 수 있습니다.
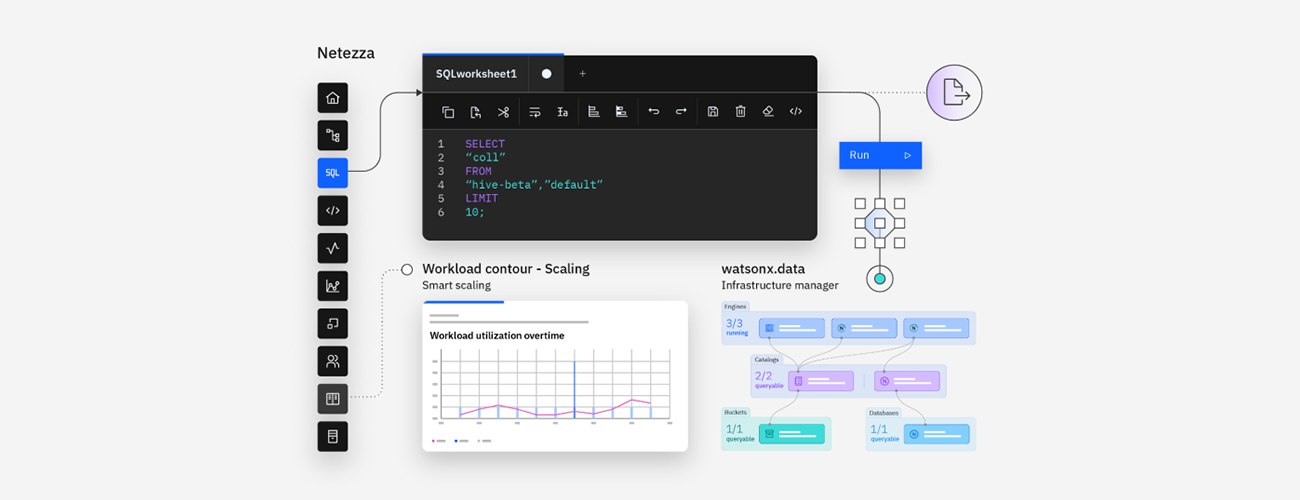
Netezza의 탄력적 컴퓨팅을 활용하면 사용한 만큼만 비용을 지불하면서 확장 및 축소할 수 있습니다. AI 워크로드 분석은 워크로드 필요에 따라 확장을 예측하고 예약할 수 있습니다.
Parquet 및 Iceberg와 같은 오픈 포맷을 사용하여 기업 전체에서 데이터를 안전하게 공유할 수 있습니다. 데이터 엔지니어, 데이터 과학자 및 개발자는 데이터 복사본을 공유하지 않고도 추가적인 ETL 없이 더 많은 것을 구축할 수 있습니다.
비용 효율적인 클라우드 객체 스토리지에 AI용 데이터를 저장 및 공유하고, Presto 및 Apache Spark와 같은 목적에 맞는 쿼리 엔진을 사용하여 가격과 성능에 맞게 분석 및 AI 워크로드를 최적화하세요.
복잡한 쿼리를 실행할 때 수천 명의 사용자를 지원할 수 있는 특허 받은 대규모 병렬 처리를 활용하면 인사이트 확보 시간과 의사 결정 속도를 며칠에서 몇 분으로 단축할 수 있습니다.
IBM Knowledge Catalog 통합을 통해 데이터 거버넌스, 보안 및 자동화 기능이 내장된 단일 플랫폼에서 데이터 가시성, 감사 가능성, 데이터 마스킹, 액세스 제어 등을 보장합니다.
Netezza 솔루션의 관리형 데이터를 사용하여 분석을 실행하고 데이터베이스 내에서 직접 자체 ML 모델을 구축, 학습, 조정 및 배포할 수 있습니다. IBM Netezza Performance Server는 Python, C, C++, R, Lua 및 Java를 포함한 모든 주요 프로그래밍 언어를 지원합니다.
공유 메타데이터, 오픈 테이블 형식 및 객체 스토리지를 통해 분석 및 AI용 데이터의 단일 복사본을 Netezza와 watsonx.data의 여러 쿼리 엔진에 공유하므로 ETL이 필요하지 않습니다.
데이터 레이크에 저장된 방대한 양의 정형 및 비정형 데이터에 심층 인사이트를 제공합니다.
기본 제공되는 풍부한 분석 및 지리 공간 기능 덕분에 추가적인 데이터 전처리 및 변환이 필요 없어 인사이트를 더 빠르게 확보할 수 있습니다.
리니지와 watsonx.data 통합으로 지원되는 관리형 Netezza 데이터로 자체 AI 모델을 구축, 학습, 조정 및 배포하세요.
Netezza의 인메모리 처리와 내장된 ML 모델 실행을 결합하여 데이터 이상 징후를 파악하고 예측 분석을 수행할 수 있습니다.

Conestoga가 가동 중단 시간 없이 100% 워크로드 호환성을 유지하면서 온프레미스 Netezza에서 AWS의 IBM Netezza SaaS로 전환

Capital Bank of Jordan이 Netezza의 통합 데이터 허브와 강력한 분석으로 빠른 성장에 대비

Bic Camera가 IBM Cloud Pak for Data에 Netezza Performance Server를 사용하여 데이터 보고 시간이 100배 증가

Majid Al Futtaim Retail이 Netezza Performance Server를 활용하여 데이터 기반 접근 방식을 통해 매일 75만명 이상의 고객에게 도달
Optim은 전사 데이터 관리를 위한 솔루션으로 데이터 아카이빙, 테스트 환경 구축을 위한 솔루션,
애플리케이션 폐기 등을 기반으로 인프라스트럭쳐 최적화를 지원합니다.
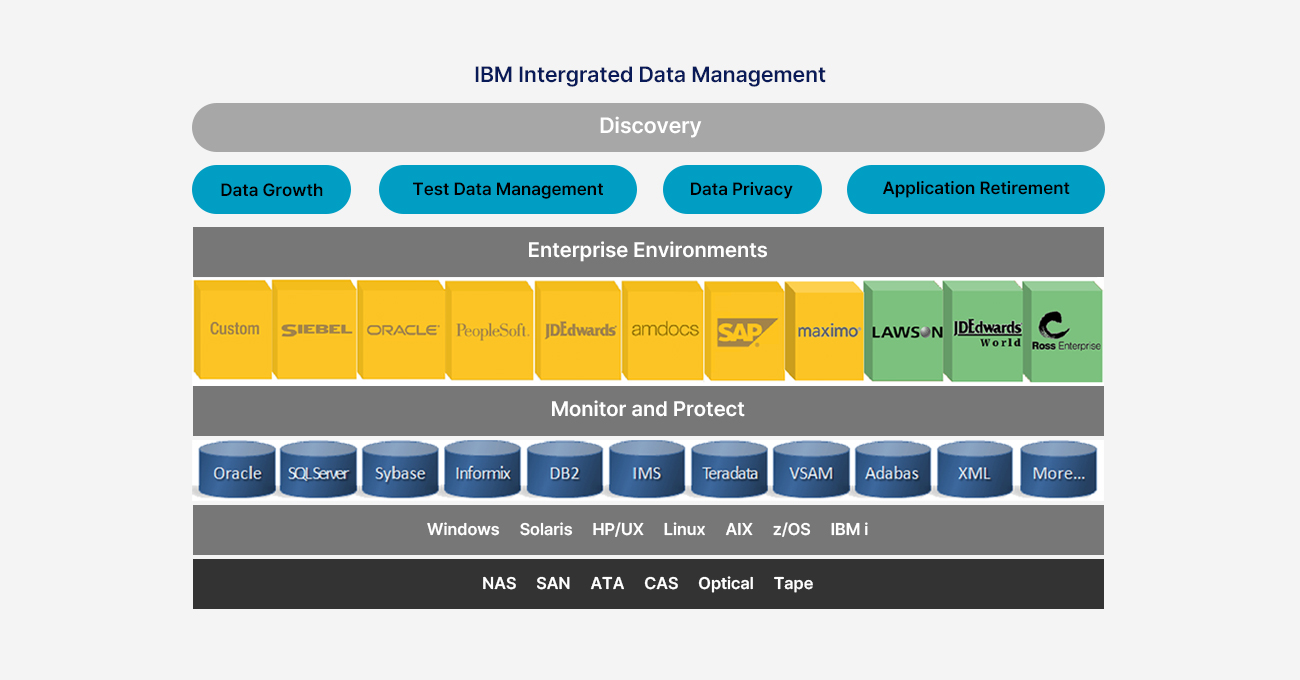
데이터 아카이빙은 정보 가치를 지닌 비활성 데이터, 활용도가 저하된 데이터를 2차 디스크로 이동 저장하고,
데이터에 대한 검색 및 조회, 그리고 아카이브 데이터에 대한 접근 모니터링을 제공하는 프로세스입니다.
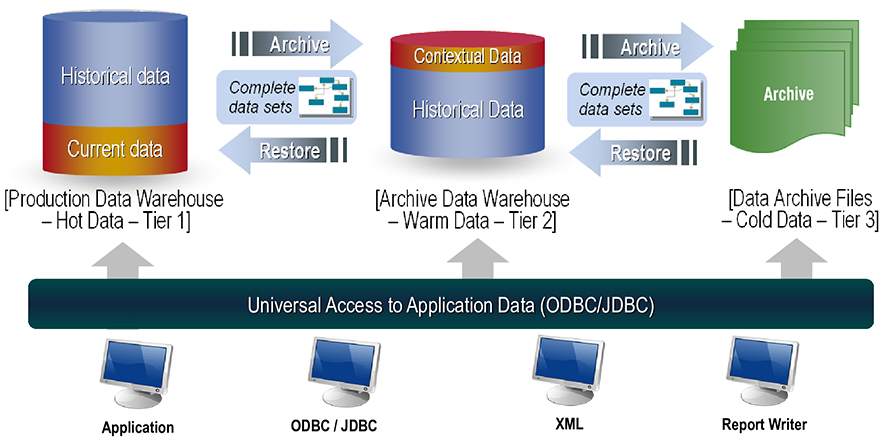
Oracle, DB2, MS-SQL 등의 다양한 DB, 애플리케이션 및 플랫폼을 지원하는 유일한 엔터프라이즈 솔루션
데이터 성격과 조회 특성에 맞게 DB, File 및 복합 구성의 다양한 형태로 아카이브 구성전략 수립
아카이빙, 조회, 모니터링, 복원, 백업 및 유지보수를 위한 관리가 가능한 통합 관리 인터페이스
작업 Scheduling과 아카이브 파일에 대한 보존연한 정의를 통해 관리 부담을 최소화하고 자동화 구축
메타데이터 검색을 통해 단일 테이블 단위가 아닌 업무 단위의 테이블 그룹에 대한 데이터 모델 도출
파일 저장시 60~90% 압축률로 아카이브 데이터 압축 저장함으로써 2차 스토리지 절감 및 가용성 향상
애플리케이션 조회 및 SQL*PLUS, ODBC/JDBC, XML와 같은 표준 인터페이스 조회 등 다양한 접근 제공

레거시 및 중복 애플리케이션을 통합하거나 폐기하는 데 도움이 됩니다. 데이터 보관은 마이그레이션할 데이터 양을 줄여 애플리케이션 업그레이드를 가속화합니다.

데이터 보존, 액세스 및 폐기를 관리하는 비즈니스 정책을 적용할 수 있습니다. 보존 정책을 사용하면 보존 요구 사항이 만료되면 보관된 데이터를 자신 있게 삭제할 수 있습니다.

구조화된 데이터에 고급 보관 기능을 적용하여 더 나은 데이터 제어를 제공하고 하드웨어 저장 및 유지 관리 비용을 줄이는 데 도움이 됩니다.
민첩한 개발 및 테스트를 위한 주문형 워크플로 및 서비스를 포함하여 테스트 데이터 관리 프로세스를 최적화하고 자동화합니다.
전체 개발환경 구성 단계별로 필요한 다양한 기능 지원 및 자동화를 통해 업무 생산성을 향상시킬 수 있습니다.
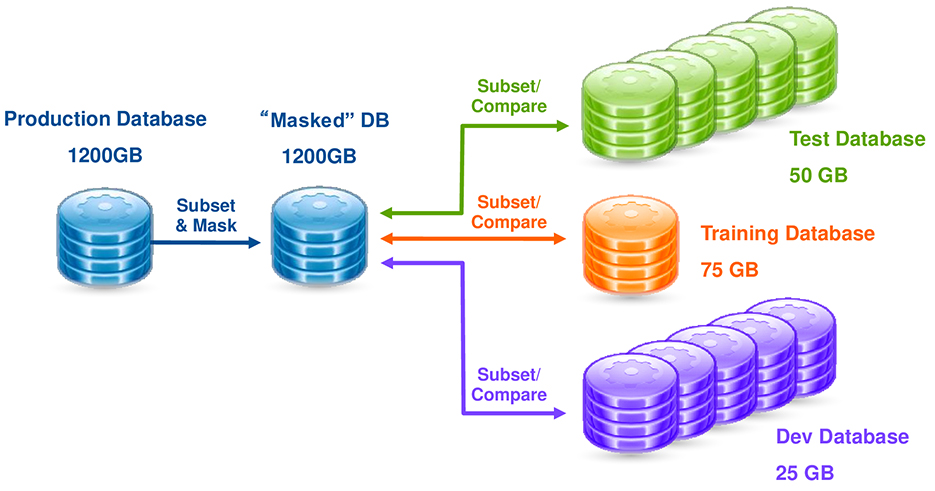

비즈니스 프로세스를 반영하는 적절한 크기의 가상 테스트 DB를 생성하여, 비용이 많이 드는 복제가 최소화되어 개발 프로세스 초기에 결함을 해결할 수 있습니다.

개발 및 테스트 요구 사항에 따라 확장되며 일반적으로 사용되는 애플리케이션, 데이터베이스, 운영 체제 및 하드웨어 플랫폼 전반에 걸쳐 확장됩니다.

신용카드 번호, 이메일 주소, 기밀 기업 정보 등의 민감한 데이터는 맥락적 의미를 유지하는 동시에 오용 및 사기를 방지하기 위해 마스킹할 수 있습니다.

개발 및 테스트를 위한 민첩한 요구 사항을 지원하므로 개발자와 테스터는 필요에 따라 데이터에 액세스하고 새로 고침하여 테스트에 더 많은 시간을 할애하는 동시에 운영 효율성을 개선할 수 있습니다.
개발, 테스트, QA 또는 교육과 같은 비 운영 환경에서 민감한 데이터를 효과적으로 마스킹 할 수 있는 광범위한 기능을 제공합니다.
기밀 데이터를 보호하기 위해 민감한 정보를 현실적이고 완벽하게 기능하는 마스크 된 데이터로 대체하는 다양한 변환 기술을 제공합니다.
또한 상황에 맞는 정확한 마스크 기능은 마스크 된 데이터가 원래 정보와 유사한 형식을 유지할 수 있도록 합니다.
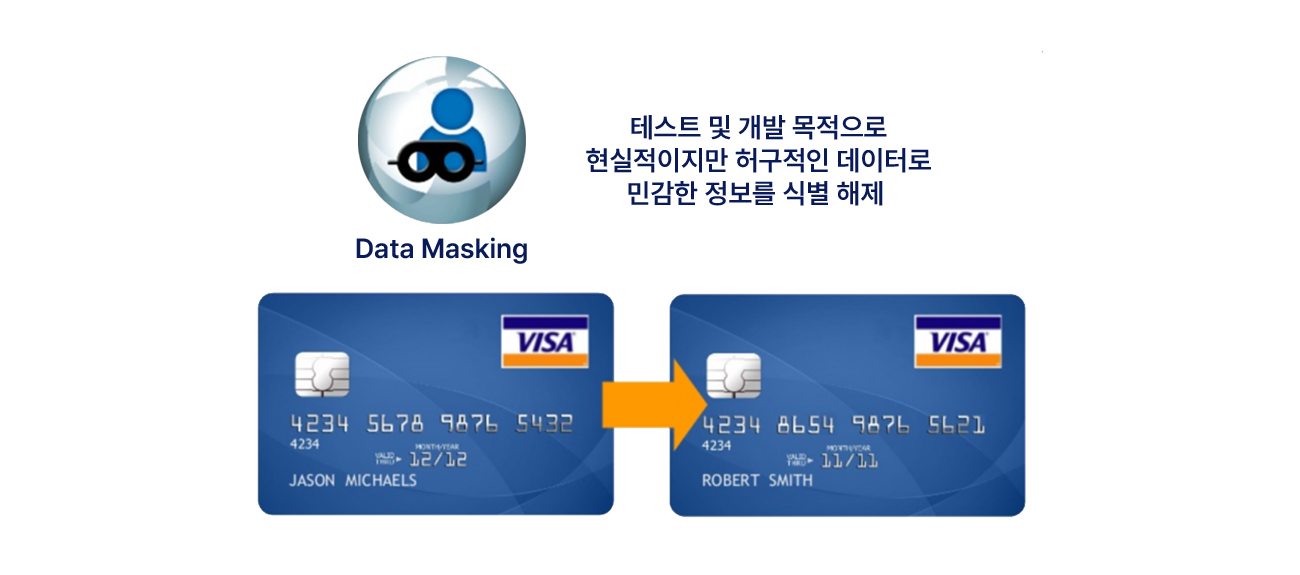
사전 패키지된 데이터 마스킹 루틴은 문맥적 의미를 유지하면서 복잡한 데이터 요소를 변환합니다. Information Governance Catalog와 통합하면 30개의 사전 정의된 데이터 분류와 30개의 사전 정의된 데이터 개인 정보 보호 규칙이 제공됩니다.
독립형 API는 사전 정의되고 사용자가 개발한 데이터 마스킹 서비스에 대한 유연하고 확장 가능한 액세스를 제공합니다. 또한 CSV, XML 및 Hadoop에서 데이터를 마스킹합니다. 사용자 정의 함수(UDF)는 데이터베이스 관리 시스템 내에서 데이터를 동적으로 마스킹합니다.
HIPAA, GLBA(Gramm-Leach-Bliley Act), DDP(Digital Due Process) 요구 사항, PIPEDA(Personal Information Protection and Electronic Documents Act) 등의 규정 준수 요구 사항을 개선하고 충족하는 데 도움을 줄 수 있습니다.
FPE를 지원하며 AES-256 알고리즘을 기반으로 식별 가능한 패턴 없이 다양한 마스크 값을 생성합니다. 동일한 키를 사용할 때 반복 가능한 마스크 값을 제공합니다. 사용자 정의 암호화 키는 추가 보안을 제공합니다.
Oracle E-Business Suite, PeopleSoft Enterprise, Siebel 등을 포함한 일반적으로 사용되는 애플리케이션과 통합됩니다. IBM Db2®, IBM Information Management System, Postgres, Informix, Oracle, Sybase 등을 지원합니다.
규정 준수 보고서는 위험 노출에 대한 통찰력을 제공합니다. 보고서에는 데이터 마스킹 규정 준수 보고서, 데이터 마스킹 시행 보고서, 마스킹 상태별 통계, 데이터 저장소 및 데이터베이스 관리 시스템 보고서가 포함됩니다.

마스킹 기술을 적용하여 애플리케이션, 데이터베이스, 보고서에서 개인 식별 정보와 기밀 기업 데이터를 변환합니다.

비 운영 환경에 배포되는 개인 정보를 가리고, 난독화하고, 비 공개화하여 정보의 오용을 방지합니다.

사전 정의된 실행 가능한 데이터 개인 정보 보호 분류 및 규칙을 사용하여 데이터 개인 정보 보호 이니셔티브를 가속화하고 규정 준수 보고 방법을 제공합니다.

테스트 환경을 현실적이고 가상적인 데이터로 대체하여 비즈니스 프로세스를 정확하게 반영하는 안전한 테스트 환경을 조성합니다.
IBM watsonx.ai는 AI 서비스를 개발하고 원하는 애플리케이션에 배포할 수 있도록 아이디어와 요구 사항을
현실화하는 데 필요한 API, 툴, 모델, 런타임을 통합한 ai 및 데이터 플랫폼입니다.

Netezza의 탄력적 컴퓨팅을 활용하면 사용한 만큼만 비용을 지불하면서 확장 및 축소할 수 있습니다. AI 워크로드 분석은 워크로드 필요에 따라 확장을 예측하고 예약할 수 있습니다.
Parquet 및 Iceberg와 같은 오픈 포맷을 사용하여 기업 전체에서 데이터를 안전하게 공유할 수 있습니다. 데이터 엔지니어, 데이터 과학자 및 개발자는 데이터 복사본을 공유하지 않고도 추가적인 ETL 없이 더 많은 것을 구축할 수 있습니다.
비용 효율적인 클라우드 객체 스토리지에 AI용 데이터를 저장 및 공유하고, Presto 및 Apache Spark와 같은 목적에 맞는 쿼리 엔진을 사용하여 가격과 성능에 맞게 분석 및 AI 워크로드를 최적화하세요.
복잡한 쿼리를 실행할 때 수천 명의 사용자를 지원할 수 있는 특허 받은 대규모 병렬 처리를 활용하면 인사이트 확보 시간과 의사 결정 속도를 며칠에서 몇 분으로 단축할 수 있습니다.
IBM Knowledge Catalog 통합을 통해 데이터 거버넌스, 보안 및 자동화 기능이 내장된 단일 플랫폼에서 데이터 가시성, 감사 가능성, 데이터 마스킹, 액세스 제어 등을 보장합니다.
Netezza 솔루션의 관리형 데이터를 사용하여 분석을 실행하고 데이터베이스 내에서 직접 자체 ML 모델을 구축, 학습, 조정 및 배포할 수 있습니다. IBM Netezza Performance Server는 Python, C, C++, R, Lua 및 Java를 포함한 모든 주요 프로그래밍 언어를 지원합니다.
공유 메타데이터, 오픈 테이블 형식 및 객체 스토리지를 통해 분석 및 AI용 데이터의 단일 복사본을 Netezza와 watsonx.data의 여러 쿼리 엔진에 공유하므로 ETL이 필요하지 않습니다.
데이터 레이크에 저장된 방대한 양의 정형 및 비정형 데이터에 심층 인사이트를 제공합니다.
기본 제공되는 풍부한 분석 및 지리 공간 기능 덕분에 추가적인 데이터 전처리 및 변환이 필요 없어 인사이트를 더 빠르게 확보할 수 있습니다.
리니지와 watsonx.data 통합으로 지원되는 관리형 Netezza 데이터로 자체 AI 모델을 구축, 학습, 조정 및 배포하세요.
Netezza의 인메모리 처리와 내장된 ML 모델 실행을 결합하여 데이터 이상 징후를 파악하고 예측 분석을 수행할 수 있습니다.

"고무적인 이번 파일럿 결과 덕분에, 생성형 AI 여정의 다음 장이 기대됩니다. IBM의 AI에 대한 윤리적이고 개방적인 접근 방식은 혁신 이니셔티브의 핵심에서 인간의 가치를 우선시하는 것을 촉진합니다."
— Alceu Meinen, Confederação Sicredi의 AI 및 고객 관계 담당 감독관

“watsonx.ai는 연구에 매우 유용한 것으로 판명되었습니다. 전체 대화를 미리 설정하지 않아도 고객과 개발팀이 작업을 단순화하고 어시스턴트의 지식을 확장하는 데 도움이 되는 방식이 마음에 들었습니다. 이는 저희와 고객 모두에게 중요한 발전입니다."
— Jindrich Chromy, AddAI.Life CEO 겸 공동 설립자

"이 여정을 이제 막 시작했습니다. IBM과의 협력은 법률 인텔리전스가 변화의 시대를 눈앞에 두고 있다는 확신을 더욱 강하게 만들었고, Blendow Group은 이러한 변화를 이끌 준비가 되었습니다."
— Johan Wallquist, Blendow Group의 최고 디지털 혁신 책임자

"IBM은 안정적이고 안전한 AI 플랫폼을 중심으로 AI 솔루션 네트워크를 육성하기 위해 노력하고 있습니다. 이는 저희의 시장 진출 전략과 잘 부합하며 앞으로 더 많은 협력을 기대합니다."
— Tom Foley, Silver Egg Technology 설립자 겸 CEO
거버넌스 데이터 및 AI 워크로드에 최적화된 용도에 맞는 데이터 저장소로, 쿼리, 거버넌스 및 오픈 데이터 형식으로 데이터에 액세스하고 공유할 수 있습니다.
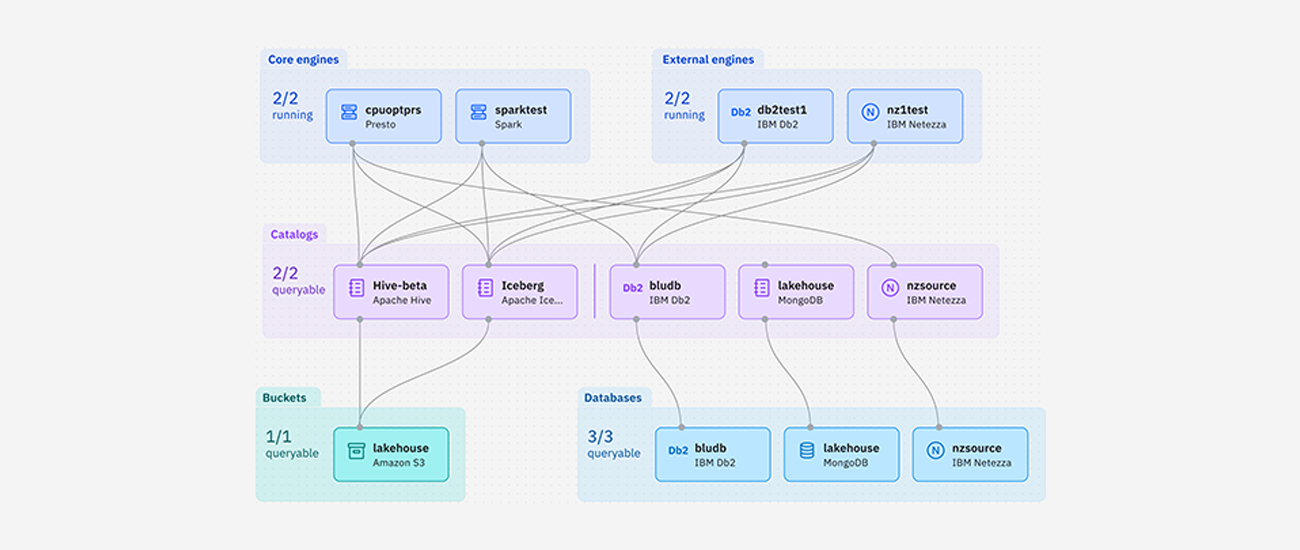
어디서든 모든 데이트를 활용하세요. 데이터 웨어하우스의 속도, 데이터 레이크의 유연성, AI를 지원하는 특수한 기능을 갖춘 watsonx.data는 비즈니스 전반에서 AI와 분석을 확장하는 데 큰 도움이 됩니다.
마이그레이션과 복제는 잊어버리세요. watsonx.data 을 사용하면 여러 워크로드에서 단일 데이터 복사본을 공유하고, 데이터 액세스를 통합하고, Hive Metastore 및 Iceberg 테이블과 같은 개방형 표준과의 호환성을 확장할 수 있습니다.
데이터를 통합, 큐레이션 및 준비하여 AI 아웃풋의 관련성과 정확성을 개선하세요. 통합 Milvus 벡터 데이터베이스는 RAG 사용 사례를 지원합니다.

"고객은 민감한 데이터에 대한 안전 조치를 절대적으로 신뢰할 수 있어야 합니다. IBM 팀과 협력한 결과, 비즈니스 지향적인 사용자에게 셀프서비스 분석 소프트웨어를 제공하는 방법을 완전히 혁신할 수 있었습니다."

"IBM의 watsonx.data를 매우 흥미로운 멀티 엔진 오픈 데이터 플랫폼으로 보고 있으며, 이를 툴링의 최우선 대상으로 포함하기 위해 노력해 왔습니다."

"watsonx.data로 작업하면 온프레미스 또는 엣지에 관계없이 고객의 데이터 연결을 가속화하여 고객이 하이브리드 클라우드 환경 전반에서 모든 데이터에 액세스해 신뢰할 수 있는 인사이트를 빠르게 얻을 수 있습니다."

"watsonx.data 사용법이 매우 간단해서 깜짝 놀랐습니다. 데이터 기밀성 때문에 온프레미스 솔루션이 필요한 고객도 많이 있습니다."
엔드투엔드 AI 거버넌스는 확장성을 위해 매우 중요합니다. watsonx.governance 툴킷은 기존 시스템과 원활하게 통합되어 책임감 있는 AI 워크플로를 자동화하고
가속하여 시간을 절약하고 비용을 절감하며 규정을 준수할 수 있도록 지원합니다. 또한 하이브리드 클라우드 전반에 걸쳐 AI를 적합한 곳에 배포할 수 있다는 이점이 있습니다.
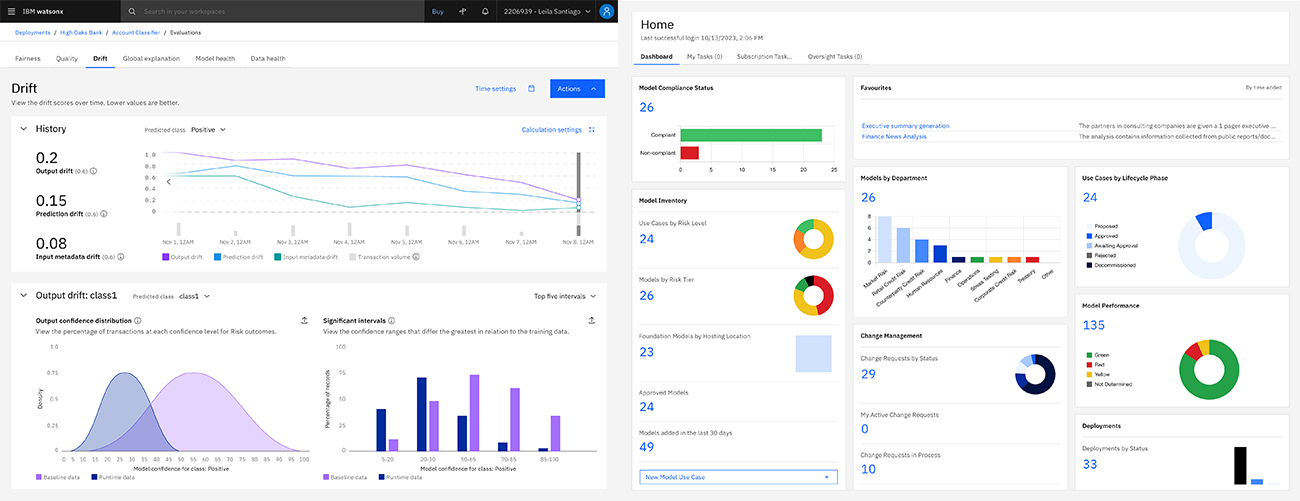
위험 메트릭을 제공하는 자동화된 툴을 활용하여 위협에 한발 앞서 대응하고 보안 취약점 및 구성 오류를 파악할 수 있습니다.
규정 변경을 식별하고 이를 시행 가능한 정책으로 변환하는 프로세스를 자동화하는 도구로 규정 준수를 간소화하세요.
올바른 사용 사례 선택부터 모델의 개발, 배포, 모니터링, 교체에 이르는 엔드투엔드 AI 거버넌스를 IBM 또는 OpenAI, Amazon SageMaker와 같은 타사 모델 전반에서 자동화하고 확장합니다.

US 오픈에서는 watsonx.governance를 사용하여 토너먼트 데이터의 편향을 제거하고 코트의 공정성을 71%에서 82%로 높였습니다.

Deloitte는 watsonx.goverance를 활용하여 규정준수, 위험, 라이프사이클 거버넌스 등 AI 거버넌스의 다양한 측면을 다루었습니다.

Tech Mahindra는 watsonx.goverance와 TechM amplifAI를 결합하여 고객이 비즈니스 전반에 걸쳐 생성형 AI를 확장할 수 있도록 지원 했습니다.

IBM의 개인정보 보호 및 책임 기술 부서는 IBM 머신 러닝 모델의 글로벌 개인정보 보호 및 AI 규정 준수 작업을 간소화하고 자동화할 수 있습니다.
개발자 생산성을 높이고, 코딩 복잡성을 줄이고, 개발자 온보딩을 가속화하세요.
특정 사용 사례를 위해 특별히 구축된
watsonx Code Assistant는 AI를 사용하여 애플리케이션 현대화 및 IT 자동화를 지원합니다.
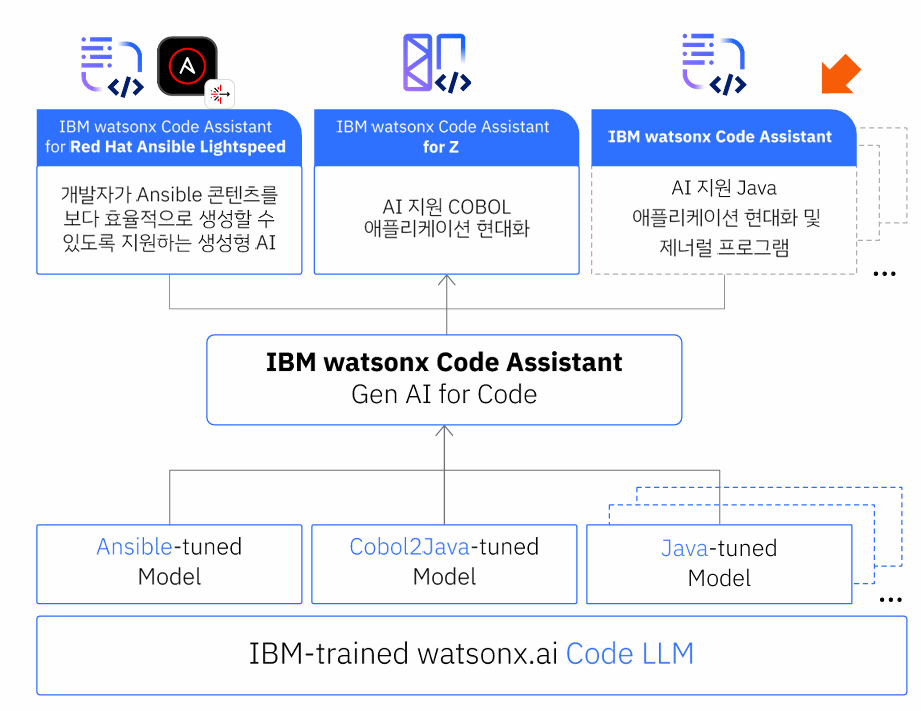
간단하고 자연어기반의 프롬프트를 사용하여 기존 규칙에 맞춰 코드를 생성하고, 코드를 작성하거나 주석을 넣을 때 자동으로 코드를 완성합니다.
코드의 목적, 논리 및 기능을 명확하게 설명하고, 표준화된 형식에 맞춰 코드의 문서를 추가합니다.
하나의 프로그래밍 언어를 다른 언어로 변환합니다.
애플리케이션에 대한 명확하고 간결한 설명을 통해 비즈니스를 빠르게 이해하실 수 있습니다.
WebSphere Application Server를 가볍고 유연한 Liberty Server로 현대화를 빠르게 도와 줍니다.
자바 버전 업그레이드에 필요한 변경사항을 식별하고 코드 구성과 변경사항을 자동으로 적용하여 버전에 맞는 자바코드로 변환합니다.
데이터 패브릭 아키텍처로 구축한 플랫폼을 활용하여 성과 예측을 보다 가속화합니다. 데이터 상주 위치에 구애받지 않고 데이터를 수집, 구성, 분석합니다.
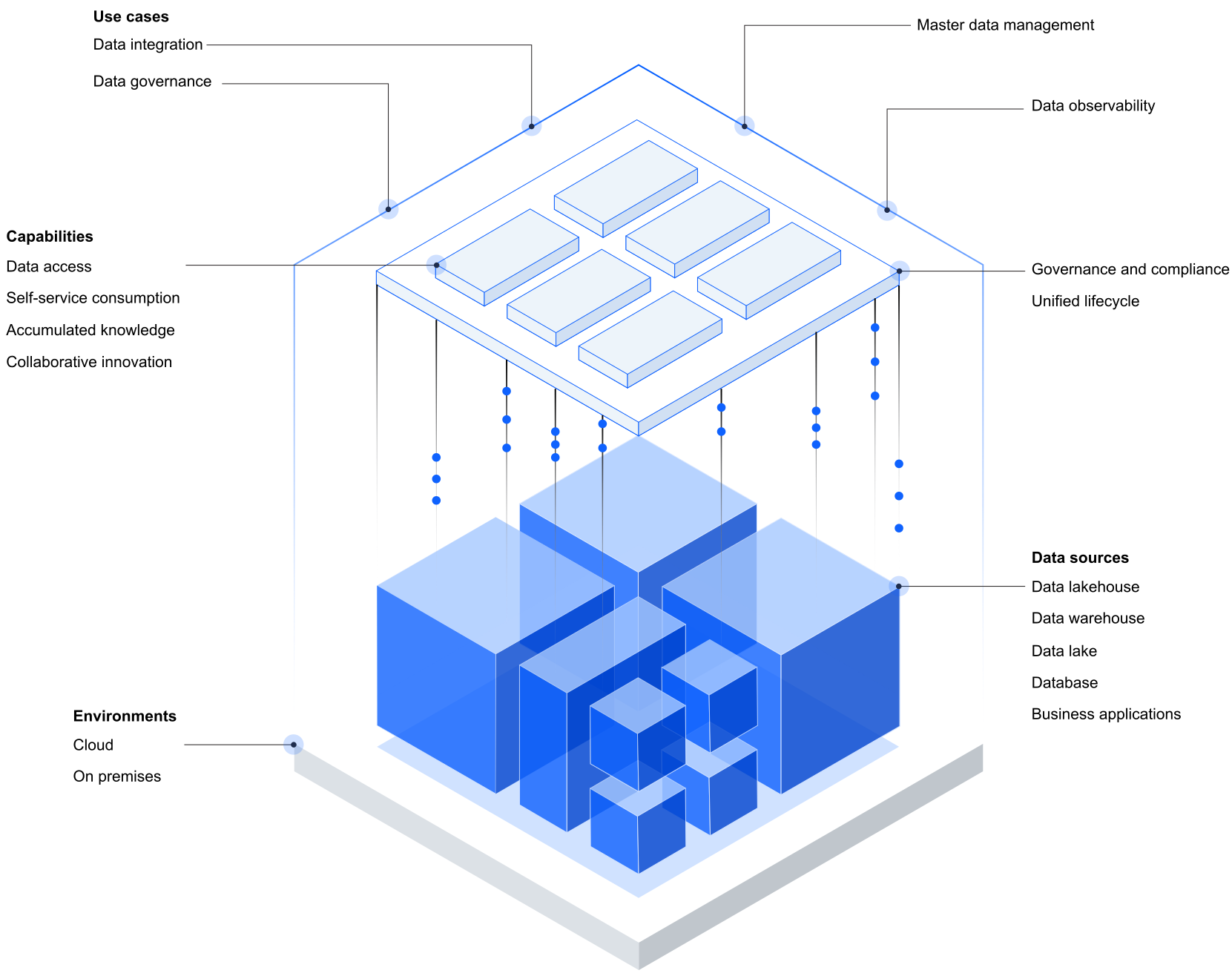
데이터를 이동하지 않고도 온프레미스 및 클라우드의 비즈니스 사일로 전반에 걸쳐 데이터에 액세스할 수 있습니다.
모든 데이터에 대해 개인정보 보호와 사용 정책을 적용하여 데이터 사용을 전반적으로 보호합니다.
모든 기술 수준의 사용자가 맞춤형 인터페이스(Code, Canvas, No Code)를 통해 신뢰할 수 있는 데이터에 액세스할 수 있도록 지원할 수 있습니다.

AI 데이터 분석을 활용해 추천 엔진을 개선할 수 있다는 점은 분명했습니다. 개발 지원을 위해 2021년 3월, Change Machine은 IBM 데이터 과학 및 AI 엘리트 팀과 협력했습니다. IBM은 비영리 단체가 데이터 과학과 AI를 활용해 미션을 달성할 수 있도록 지원하는 견습생 협력 프로그램인 사회적 영향력을 위한 IBM 데이터 및 AI에 참여하고 있습니다.
이 프로젝트는 IBM과 Change Machine 직원이 지식을 공유하고 요구사항을 고안하면서 시작되었습니다. 목표는 조직 데이터를 일관성 있는 전체로 합리화하고 권장 사항을 맞춤화하는 기계 학습 분류 모델을 개발하는 것이었습니다. 모델은 자가 학습되고 Trusted AI를 기반으로 하며, 이는 권장 사항의 이유를 설명할 수 있음을 의미합니다.
확장성을 통해 엔진은 파트너와 사용자의 예상 증가를 처리할 수 있습니다. 또한, 운영 대시보드에 실시간 데이터를 표시하여 운영에 대한 인사이트를 얻을 수 있습니다.
IBM Aspera는 글로벌 WAN을 통한 빅데이터 이동 문제를 해결하기 위해 색다른 접근법을 취합니다. 데이터 전송을 최적화하거나 가속화하기 보다,
Aspera는 획기적인 전송 기술을 사용해 근본적인 병목 현상을 제거하고 사용 가능한 네트워크 대역폭을 활용해 속도를 최대화하며 이론적 한계 없이 신속하게 확장합니다.
고속 전송을 활용하여 온프레미스 데이터 센터와 주요 클라우드 간 데이터를 마이그레이션합니다.
시스템, 직원, 고객 및 파트너사 사이에서 모든 규모의 데이터를 최대 속도로 전달하고 배포합니다.
규모, 형식 또는 전송 거리에 관계없이 영상과 빅 데이터 워크플로우에 필요한 처리를 자동화합니다.
사내 데이터 센터 및 주요 클라우드에 저장된 대용량 파일과 폴더를 전송하고 공유합니다.
빅데이터 저장소의 고속 백업과 복제를 즐겨보세요.
스트리밍 기술은 대용량 스트림을 오류 없이 전송할 수 있는 혁신적인 대안입니다.

2018년 FIFA 월드컵 기간 동안 FOX Sports는 국제 데이터 연결이라는 러시아 특유의 어려움에도 불구하고 모스크바와 로스앤젤레스 간 상용 인터넷을 통해 총 2,700개 이상의 라이브 피드를 전송했습니다. 붉은 광장 스튜디오 세트와 러시아 전역의 12개 스타디움에서 프로그램 피드는 라이브 공연이 시작되고 몇 초 만에 "작업 준비된" 상태로 편집팀의 시스템에 직접 도착했습니다. 그리고 이 모든 것이 상당한 비용 절감과 함께 이루어졌습니다.
주식회사 에이플러스소프트 | 대표 : 정경원 | Tel : 070-8888-5300
주소 : 서울시 영등포구 영등포로 150(당산동 1가, 생각공장 당산) B동 508호
Copyrightⓒ Aplussoft Co., Ltd. All rights reserved.